


大数据技术漫谈:数据一致性那点事儿
AI时代公司要胜出,拼算法和数据。算法就那么些经典的可以挖掘,所以最宝贵的可能就是数据资源了,也就是前几年满大街的大数据思维。大数据有短时间过热的嫌疑,但从长远来看,未来是属于大数据的。最近零零碎碎的看了一些大数据相关资料,结合自己的理解,来谈谈大数据相关一些零星技术思考,本篇就从一致性技术谈起吧。写的有点杂乱,但还是分3点说明:
- 一致性起源:设计原则CAP, BASE, ACID
- 一致性保证:Paxos,锁
- 相关小细节:死锁,回调,MR
下一篇开始将从体系结构分别说一下大数据系统的协调,通信,数据通道,存储,以及计算。
1.一致性起源
随着需要处理的数据越来越大,我们需要多台机器并行处理。那么数据分布式和服务分布式就比较重要了。为了保证我们的服务和数据的可用性,大牛们设计了一些原则,最顶层的就是CAP(Consistency,Availability,Partition Tolerance),说白了就是要在保证网络分区(服务的部分机房断网导致该部分通信中断)的情况下在数据一致性和服务可用性做一定的取舍。当然单机服务不用考虑P了。 在这样的框架有两种模式,一种是BASE(Bascialy available, Soft state, Eventually Consistency)即为现在大部分强调可用性的分布式系统也就是保证P的情况下强调A,损失一部分C。另一种即为 ACID(Atomicity, Consistency, Isolation, Duration)强调数据的完整一致,大部分的关系型数据库系统就是这么做的。
- 数据分布式
在多台机器上分布的存储数据。这里的数据,工业上讲就是我们所说SQL或者NoSQL数据库。
- SQL:常见的mysql,oracle,SQLserver等行存储数据库,扩展采用分库(不同结构数据)然后采用分表然后分区(相同结构数据),一旦采用这些技术后,势必导致表的查询或者连接麻烦,一般我们会有持久层中间件来实现这些技术负责路由找表如TDDL等。
- NoSQL:常见的HDFS+HIVE形成离线数据库或者HBASE,MongoDB在线数据库。采用列存储方式,特别适合大规模稀疏性数据。天生就适合分布式,因为没有索引也不支持事务,以文件的形式存在。
- 优缺点:如果是那种全信息查询,比如profile之类的,使用行存储会比较好,如果是只取某一列信息,比如跟帖这类的且schema并不固定,使用列存储会比较好。
- 程序分布式
- 大规模离线计算:使用hadoop+mapreduce实现多台机器并行计算,mapreduce通过计算map数量,partition数据决定reduce数量,当jobtracker在maptask任务后进行shuffle(sort+combine),然后缓行相关的reduce任务进行数据获取。
- 大规模在线服务集群:kafka进行日志手机后,可以使用zookeeper来管理协条多台服务并发,而服务器与服务器之间通信可以使用消息队列,如MQ。具体细节不多说,大家可以参考张俊林的《大数据日知录》
2.一致性保证
一致性我们从第一天写程序对数据处理,就会有接触到。这里我们从2个方面考虑一致性
- 数据
- 单机存储角度:保证数据是一致的,如果是文件,只有一份,当然就是一致的。如果是数据库,就得保证每次操作是符合ACID,注意不是CURD(增删改查),Innodb采用事务方式(锁)来保证原子性(要么成功要么失败),一致性(比如整体的约束不变),隔离性(事务锁机制),持久化(不会无缘无故回滚Rollback)。注意这里只是说的Innodb(在autocommit=0的情况下适合大量插入更新),而不是myisam(适合大量select)。
- 多机存储角度:SQL数据库则是主从配置多个备份,master负责写,slave负责读,master同步到slave。如果是文件nosql,则一般会有三处备份,其中一个是主备份。当主备份更新的时候,会通知其他备份更新。这里由于更新需要时间,所以不能保证强一致性。当然如果是大规模数据的话,会有哈希分片存储机制,如round-robin,一致性哈希技术来进行分布式存储。
- 程序
- (进程线程)数据库一致性操作:前面提到数据库问题,也就是每一条SQL语句都会默认成事务,那么就会取得锁,原则上为了保证数据不出现死锁,应该避免长时间的事务操作。增删改查尽量使用主键索引。
- 线程一致性操作:通常我们会使用synchornize来同步线程操作,线程对这个对象的操作前要先获得该对象的锁,如果synchornize()则默认是this,该对象,注意这里是排他锁X。如果要提高读写效率,可以使用Readlock和writelock。我们使用wait()进行对象锁的释放,notify()完之后进行通知唤醒wait的线程重新开始竞争获取该对象的锁。。
- 进程通信:RPC,有很多种RPC框架,比如thrift,PB,dubbo等,通信格式有pb,thrift,json,xml等,经过他人相关实验对比看来,使用Thrift的TCompactprotocol无论从传统的压缩比还是cpu占用都是最优的。传输同样的数据比json压缩50%,cpu占用也差不多这个量级。
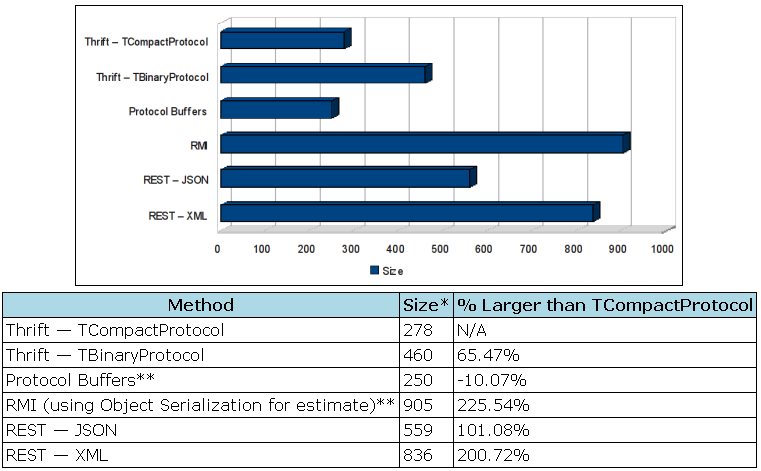
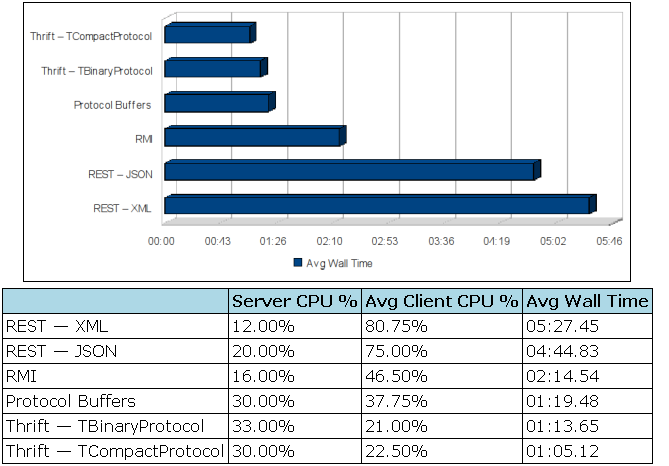 参考http://blog.csdn.net/m13321169565/article/details/7835957#0-tsina-1-87119-397232819ff9a47a7b7e80a40613cfe1
参考http://blog.csdn.net/m13321169565/article/details/7835957#0-tsina-1-87119-397232819ff9a47a7b7e80a40613cfe1
3.相关小细节
- 死锁问题:之前做数据更新总是遇到死锁,简单来说就是对资源进行加锁,在没有释放锁的情况下继续申请锁(不管是两个线程申请同一个对象的锁,还是申请不同对象的锁)都有可能死锁。所以尽量用完就释放,不管是读锁还是写锁。
- 通信机制:服务器端sockect-bind-listen-accept-fork-recv-send, 客户端socket-[bind]-connect-send-recv。这是通用的模式,当然很多语言会有自己的包封。
- 回调消息:回调简单说来就是我让你做事,你做完了告诉我一声,怎么告诉我,我来定这个方案,这个方案就是回调函数。需要反馈的人负责实现,做事的你不用负责,只要知道就可以。同步就是等你做完事通知我之后我再做事,异步就是我接着做我的事不用等你通知我,你完事了告诉我就可以。是不是有点绕,哈哈,请参考我的源码https://github.com/bobz653/programming/tree/master/callbackjava
- MR:jobtracker下面有多个tasktracker(map,reduce),tasktracker只能运行在DataNode上。map阶段会执行sort-merge这些shuffle动作,减少磁盘IO,然后通知jobtracker已经完成,jobtracker会告知reducetask来取数据,reduce会从各个map节点拉去已经merge好的数据再次reduce合并,输出结果.